


车牌照自动识别算法研究
摘 要:以在民用领域十分有应用价值的汽车牌照作为目标自动识别(ATR)对象,提出2种分别基于色彩和字符特征的车牌识别算法,通过不同特征的选取,使用Matlab软件作为研究工具,研究数字图像的目标识别方法,实现基于特征的快速定位和识别。两种算法都简单易行,各有所长,并有所优化选择。
关键词:数字图像;自动目标识别;牌照特征;识别算法
中图分类号:TN911.7文献标识码:A
文章编号:1004-373X(2008)22-108-04
Study on Automatic Target Recognition Algorithm of License Plate
ZHANG Ming
(96411Unit of PLA,Xi′an,721006,China)
Abstract:As a more prevalent visible scientific calculational software,Matlab has a powerful processing function in digital image.The thesis takes Matlab as an applied tool,and takes the license plate which has a very high applied value in civil field as Automatic Target Recognition(ATR) target to research the method of object recognize of digital image.Through different characters and arithmetic to achieve fast location and recognition based on character.
Keywords:digital image;automatic target recognition;license-plate character;recognition algorithm
1 引 言
在现代社会中,图像自动识别技术在军事和民用的许多领域都得到了日益广泛的应用。车牌识别技术的研究是图像识别技术中最常见的一种应用,具有重要的现实意义和理论价值。
一个完整的车牌识别系统一般由图像输入、图像处理(提取特征)和牌照定位识别3部分组成。本文只把重点放在后两步,着力研究这两部分的算法和实现过程。
车牌识别系统和其他的图像识别过程一样,关键在于特征的选择和提取。
我国的车牌底色和字符颜色种类并不多,而且字符主要是英文字母、数字以及少量汉字组成,这就提供了2个非常明显的特征:颜色和字符。
但由于车牌的不同,以及检测时不同的光照条件,给车牌识别增加了难度,很难用一种算法就实现一个完善的系统。
在这里以常用的蓝底白字车牌作为基本研究对象,分别利用颜色和字符这两个特征,采用Matlab 7.0作为开发软件,对车牌识别算法进行研究,并对比其算法和识别效果。
2 基于颜色特征的车牌自动识别算法
以蓝底白字的车牌为目标,用其颜色作为选取和要提取的特征,在输入原始图像后,对行和列方向的蓝色像素点进行统计,分别得到行和列方向上特征蓝色像素的位置,然后用这两个位置的坐标值对原图进行截取,即可以得到车牌图像。
2.1 车牌识别算法实现过程分析
实验采用图片主要有3张,分别是car1.jpg,car2.jpg,car3.jpg,如图1所示:

Matlab在处理JPG格式的真彩图像时实际上是作为3个RGB矩阵处理,可以用一条简单的Matlab语句来分别定义3个矩阵:
I=imread(′car1.jpg′);
[y,x,z]=size(I);
myI=double(I);
第一行是将图像car1.jpg读取到Matlab的变量I中;第二行是根据图像I的大小(x和y分别代表I在行和列方向上的像素个数)以及RGB维度(z=1,2,3,分别代表R,G,B)设置三维矩阵大小;最后一行生成一个大小等于图像I,元素值等于图像I的相应位置像素的RGB值(三个维度分别存储R,G,B)的图像矩阵。
之后,在RGB空间中根据广义上的“蓝色”范围,对R,G和B分设置一个阈值范围,在行和列方向上分别统计每个像素的RGB是否在这个阈值范围内。这个过程在Matlab中属于一个常用的数组(矩阵)循环查询的过程,对行和列只需要分别用一个二重循环(每列和每行分别一个循环),循环次数分别等于前面定义图像矩阵时获得的y和x的值。
这个过程的关键是阈值的选择。根据RGB色彩空间理论,以8位格式存储的RGB表示系统R,G和B分别有28个值,其组合出来的色彩则可以有224种。人凭肉眼不可能区分224种颜色,即使假设车牌的底色都是绝对相同的,由于光照、灰尘、水汽、环境对比等的干扰,在原始图像获得过程中也会造成图像颜色与实际颜色存在差别,因此,这里要统计的“蓝色”是一类相近色彩的总称,这给阈值确定带来了困难。阈值范围太窄,可能遗漏一些视觉色彩;而阈值范围太宽,也可能会增加一些实际不存在的视觉色彩,影响识别的效果,甚至造成错误。本文根据参考文献中的相关内容,结合实践验证后采用的阈值范围是:100≤R≤200,40≤G≤200,B≥150。
当完成这个步骤后,每行每列可以得到2个一元函数f(x)和g(y);x和y对应的行和列方向的值;f(x)和g(y)分别代表列和行方向蓝色像素点的个数。如果f或g值大于阈值,则代表检测到了车牌的颜色区域,反之,则表示还没检测到车牌的颜色区域。根据这个阈值,设计一个判断循环,就可以分别在行和列方向得到2个坐标刻度。
由于图像和算法本身的不足等原因,得到的这4个坐标刻度所围成的区域并不一定完全和真实的车牌在图像上的区域吻合,需要根据实验进行人工修正。利用修正后的4个坐标刻度去截取原图,就可以得到车牌,完成整个基于颜色特征的车牌照识别过程。
2.2 车牌识别效果及其原因分析
采用色彩特征作为识别依据是简单直观的,特别是在周围色彩干扰比较小时可以非常正确地识别车牌,但是,如果周围色彩干扰较大时,正确的识别比较困难。在对三张实验图片的识别中,对car3.jpg就没有识别到正确的车牌,却把图片中一个蓝色路标牌作为目标。
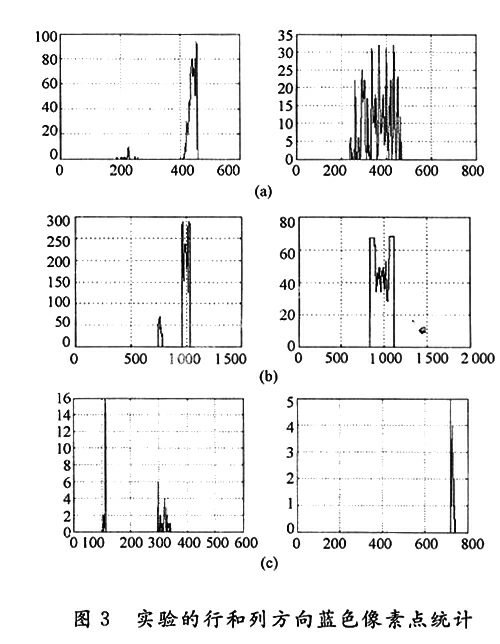
为了分析识别效果,特别提取3张实验图片在列和行方向的蓝色像素点统计函数f(x)和g(y),并绘制成曲线,分别见图3中(a)~(c)。
从图3(a)和图3(b)中可见,因为两图图像质量较高,色彩的色度和对比度都非常高,而且图形规则,因此在统计图上上显得统计曲线非常规整。而从图3(c)发现,统计图上在y方向的统计上时有2个阈值范围内像素集中区域,在进行4个坐标刻度截取时,首先是y方向产生了统计错误,进而影响到x方向的统计(程序设计规定,x方向的统计是在y方向统计的基础上进行)。

分析原因,这与程序设计上有一定关系:首先本程序采用的色彩RGB值,是笔者参照参考文献中的先验值,再根据RGB色彩空间理论和实验验证得出的一个修正值,在客观性和普遍性上有所欠缺;其次本程序对目标的尺寸识别、位移和旋转等方面上有着很大缺陷,从而导致识别上的误差乃至完全错误;最后,算法中的循环统计还不太完善,导致循环统计错误,而影响到定位。
3 基于字符特征的车牌自动识别算法实现
按照良好特征的4个条件:可区别性、可靠性、独立性和数量少来看字符,车牌字符完全符合以上4个条件。车牌字符一般都是整个图像中最集中的区域,字符简单而且变化少,满足可区别性和数量少的要求。另外车牌上的字符区域与其他图像区域相比,大的色块比较少,这样边缘比较突出,满足独立性和可靠性。
以字符为特征的识别系统流程相对色彩要复杂一些。首先要对输入图像进行预处理,其次对图像进行二值化,再次要削弱图像中背景和噪声的干扰,就可以得到一个非常简单的二值图像,其中的1值点大部分是目标点,最后只需要用类似于蓝色像素统计的办法统计出1值点,再进行1次阈值判断就可以得到车牌的位置坐标,从而完成识别。
3.1 车牌识别算法实现过程分析
以上节中识别不成功的car3为例。首先对图象进行预处理,将24位真彩图转化成256级灰度图。这样不仅便于后续的图像快速处理,提高计算运行速度,而且对多颜色图像进行了统一,避免了颜色造成的干扰。按照现行标准的平均值法,灰度转化的原理是:g=0.3R+0.59G+0.11B在Matlab中可以使用前面提到过的图像的格式转化函数将RGB真彩图像转化成灰度图像。如下所示:
I=imread(′car3.jpg′);
I2=rgb2gray(I);
将图像二值化后,图像上只有0值和1值点。0值多半为背景,1值中包含要寻找的字符特征,也有部分景物干扰。二值化过程有效突出了图像中的边缘部分,排除大部分背景干扰,达到突出目标的目的,同时也大大降低了后续处理的工作量。
Matlab为二值化过程提供了一个简便的函数BW=im2bw(I,level),level是归一化的阈值,取值在[0,1]之间,其取值直接关系到二值化的效果。图像中灰度大于等于level/256(灰度/256)的像素在二值化后置为1,反之,像素在二值化后被置为0。这样,如何选取阈值level成了这一步的关键。
实践证明,合理选择阈值能够有效地将背景基本置为0。Matlab提供了一个有效阈值计算函数graythresh,这个函数是根据Otsu方法,生成1个阈值,这个阈值将使图像二值化后区域内部的元素差异最小。
在参考文献[1]中,也提供了一个计算阈值的经验公式:T=Gmax-(Gmax-Gmin)/3,T是阈值,Gmax 和Gmin分别是图像中的最高、最低灰度值。本文选用这个经验公式作为产生阈值的方法。
然后,再对图像进行削弱背景和噪声干扰处理。首先对二值图像进行边缘检测,进一步去除背景的干扰,然后针对噪声干扰多为独立点,而字符特征多为短竖线这一特点进行中值滤波,过滤掉噪声。
在进行边缘检测时,常用的几种边缘检测算子是:Robert算子、Sobel算子、Prewitt算子、LOG算子和Canny算子,其具体内容可参考相关文献。
经过实验比对,Canny算子最满足本文去除背景的要求,因此在程序中选用的是Canny算子。
Canny算子是根据著名的Canny三原则(信噪比原则、定位精度原则、单边缘响应原则)结合获得的信噪比与定位乘积之最优逼近算子,使用一阶导数的极大值表示边缘。其基本思想是先将图像使用Gauss函数进行平滑,再根据一阶微分的极大值确定边缘点。Canny算子使用2个阈值来分别检测强边缘和弱边缘,当且仅当弱边缘与强边缘相连时,弱边缘才会出现在输出中,因此受噪声干扰较小,能检测到真正的弱边缘。边缘检测后需要进一步去除噪声。因为字符多是一些短竖线和短横线,而背景噪声很大部分是孤立噪声,因此,使用中值滤波函数medfilt 2就可以滤除主要噪声了。根据前面的分析,这里中值滤波采用的模板窗口是一个9行1列的竖线滤波窗口(medfilt 2函数参数为[9 1]),这样将过滤掉图像中非短竖线的部分,从而去掉噪声。
经过前面几步后,基本就可以获得一个比较“纯净”的二值图像,在这个图像上的字符特征区域有比较密集的“1”值点,还散布有少量残余背景和噪声也表现为“1”值点。接下来采用统计的方法对“1”值点分别在行和列方向进行统计,步骤几乎与采用色彩特征进行识别的统计过程一致,区别只在于色彩特征要求统计阈值的是256级的RGB范围,而这里只需判断是否为“1”。
确定车牌位置也于前面的色彩特征识别时确定位置的过程一样,也是用1个阈值来判断是否“遇到”了特征字符区域,然后确定4个坐标刻度,然后根据实验情况对这4个刻度进行修正,最后准确地对车牌实现定位。
3.2 车牌识别效果及其原因分析
通过实验发现,基于字符特征的车牌自动识别技术对于car1.jpg和car3.jpg都具有良好的识别效果,但对于car2,jpg的识别却发生错误,识别对象变成了右后视镜。
分析错误的原因发现,当car2.jpg转为灰度图时就已经出现错误的隐患了,车牌部分已经几乎和周围的背景完全混在一起,如图4所示。再转换为二值图像,车牌部分完全成了黑色,也就是没有任何“1”值点,字符特征已经完全被附近的背景所掩盖,导致错误发生,如图5所示。

分析car2和car1以及car3的区别,可以发现car2图像中,字符区域字符的特征不明显,而且字符的颜色和周围背景的颜色很接近;另外车牌区域和周围区域的颜色对比度很大,导致在转换为灰度图像时,车牌区域相对周围区域灰度级太低,在二值化时被判决为“0”区域,即被判决为背景,导致识别失败。这个问题在本算法中无法避免,在实际运用中必须运用其他识别方法辅助进行来解决。
4 结 语
利用Matlab作为工具,结合汽车牌照识别,本文对数字图像中的目标识别技术进行一定的研究。在前人的工作基础上,提出2种分别基于色彩和字符特征的车牌识别算法。两种算法都简单易行,各有所长,并有所优化选择。由于客观条件及时间的限制,这两个车牌自动识别算法尚不成熟,在以下几个方面还有一些问题需要解决:
(1) 解决原始图像来源不同导致的图像质量差异问题,或者从算法上抑制这些差异造成的影响;
(2) 改进算法,解决相近色彩干扰问题,解决循环统计计数问题;
(3) 进一步提高算法的普遍性,给算法增加一些可选分支,使得算法能适应多种识别需求。
这些问题还需要在后续研究中进一步提高和完善。
参考文献
[1]何斌,马天予.数字图像处理[M].2版.人民邮电出版社,2003.
[2]王耀南,李树涛,毛建.计算机图像处理与识别技术[M].北京:高等教育出版社,2001.
[3]廖佩朝.自动目标识别器的发展现状及应用分析[J].红外与激光技术,1992(2):1-2.
[4]李弼程,彭天强,彭波,等.智能图像处理技术[M].北京:电子工业出版社,2004.
[5]闻新,周露,张鸿.Matlab科学图形构建基础与应用[M].北京:科学出版社,2002.
[6]容观澳.计算机图像处理[M].北京:清华大学出版社,2000.
[7]赵雪春,戚飞虎.基于彩色分割的车牌自动识别技术[J].上海交通大学学报,1998,32(10):4-9.
[8]张炜,王庆,赵荣椿.汽车牌照的实时分割算法[J].西北工业大学学报,2001,19(1):35-37.
[9]清源计算机工作室.Matlab 6.0高级应用——图形图像处理[M].北京:机械工业出版社,2001.
[10]郭亚,王水波.基于灰度图像的车牌定位算法研究与实现.现代电子技术,2008,31(2):137-139.
[11] 陈轩飞,陈志刚.车牌字符的预处理研究.现代电子技术,2005,28(2):63-65.











